El reto consiste en la predicción de la contratación de un préstamo personal usando varias variables cuantitativas y cualitativas relacionadas con los clientes. Se suministran dos juegos de datos, uno para realizar el training de los algoritmos de machine learning que contiene la información del resultado final de la contratación y uno de "test" que omite este resultado para realizar una predicción que pueda ser evaluada.
Tras un análisis detallado de los datos, que se explica a continuación, se elige el siguiente array con nuestra predicción: respuesta.txt (también en json o npy)
El entorno
Para este reto se usará Anaconda ya que contiene todas las librerías de manipulación de datos necesarias. Para el tratamiento de los datos se usarán numpy y pandas, para machine learning se usará sklearn y TPOT y para la representación de los resultados matplotlib. Todo el procesado de datos se implementa en un notebook de Jupyter para permitir su reproducción que se encuentra aquí (y se puede visualizar online).
La estructura de los datos
El juego de datos de training contiene 471839 líneas y 100 columnas incluyendo una que parece ser el identificador del registro ("ID") y otra que parece ser el resultado de la contratación denominada "TARGET". El juego de datos de test contiene 202517 líneas y la misma estructura de columnas pero omitiendo la columna "TARGET".
Antes de comenzar se substituyen todas las comas decimales por puntos decimales para facilitar la carga de los datos con la librería pandas.
Una inspección de los datos de training permite comprobar que todos los registros con "TARGET" con valor 1 se encuentran al final del juego de datos a partir del registro con ID 663714. Por otro lado, los valores de los ID de los datos de test son complementarios a los de la muestra de training y extraídos de una manera aleatoria. Si los datos provienen del mismo juego de datos inicial (como parecen indicar los IDs) y los TARGET positivos se encuentran ordenados y al final, cabe la posibilidad de que los datos de test con TARGET positivo también se encuentren ordenados y al final. Este fallo en la aleatorización podría permitir encontrar una respuesta muy precisa pero ¿es este fallo real o una trampa? Lo intentaremos discernir en el siguiente estudio.
Predicción
Si suponemos que la información del ID de los registros no es relevante, nos encontramos ante un problema típico de machine learning en el que tendríamos que elegir uno de los algoritmos de clasificación ya que simplemente queremos predecir un valor binario.
En vez de probar manualmente varios algoritmos usamos TPOT. TPOT usa un algoritmo de evolución genética para seleccionar el algoritmo óptimo de clasificación y sus parámetros. Dos de los principales problemas de la implementación actual de TPOT son que no se encuentra paralelizada y que es relativamente lento para juegos de datos grandes, sin embargo es muy útil para seleccionar un algoritmo adecuado con un tiempo limitado como el nuestro.
Primero separamos el juego de datos de training en una submuestra de training con el 75% de los datos y otra de test con el 25% de los datos para que podamos validar nuestro modelo. La separación se realiza de manera aleatoria usando "train_test_split" de "sklearn.cross_validation". Localmente lanzamos TPOT con una sola generación pero todo el juego de datos para tener una idea del tipo de algoritmo a emplear. Paralelamente lanzamos una instancia en Amazon Web Services con más generaciones para refinar los parámetros (Se usan dos playbooks de Ansible para lanzar y aprovisionar las instancias aparte de un script auxiliar).
Finalmente, con las indicaciones de TPOT seleccionamos tres algoritmos con sus respectivos parámetros: Gradient Boosting Classifier, Bernoulli Naive Bayes Classifier y Random Forest Classifier.
Resultados de los clasificadores usados
Para cuantificar la calidad del ajuste de los clasificadores seleccionados usamos el área bajo la curva (Area Under de Curve o AUC) mostrada en una figura "receiver operating characteristic" (ROC) que en nuestro caso solo se usa para tener una indicación gráfica de la calidad del ajuste. Un área mayor indica que se maximiza el número de positivos correctos mientras que se minimiza el número de falsos negativos.
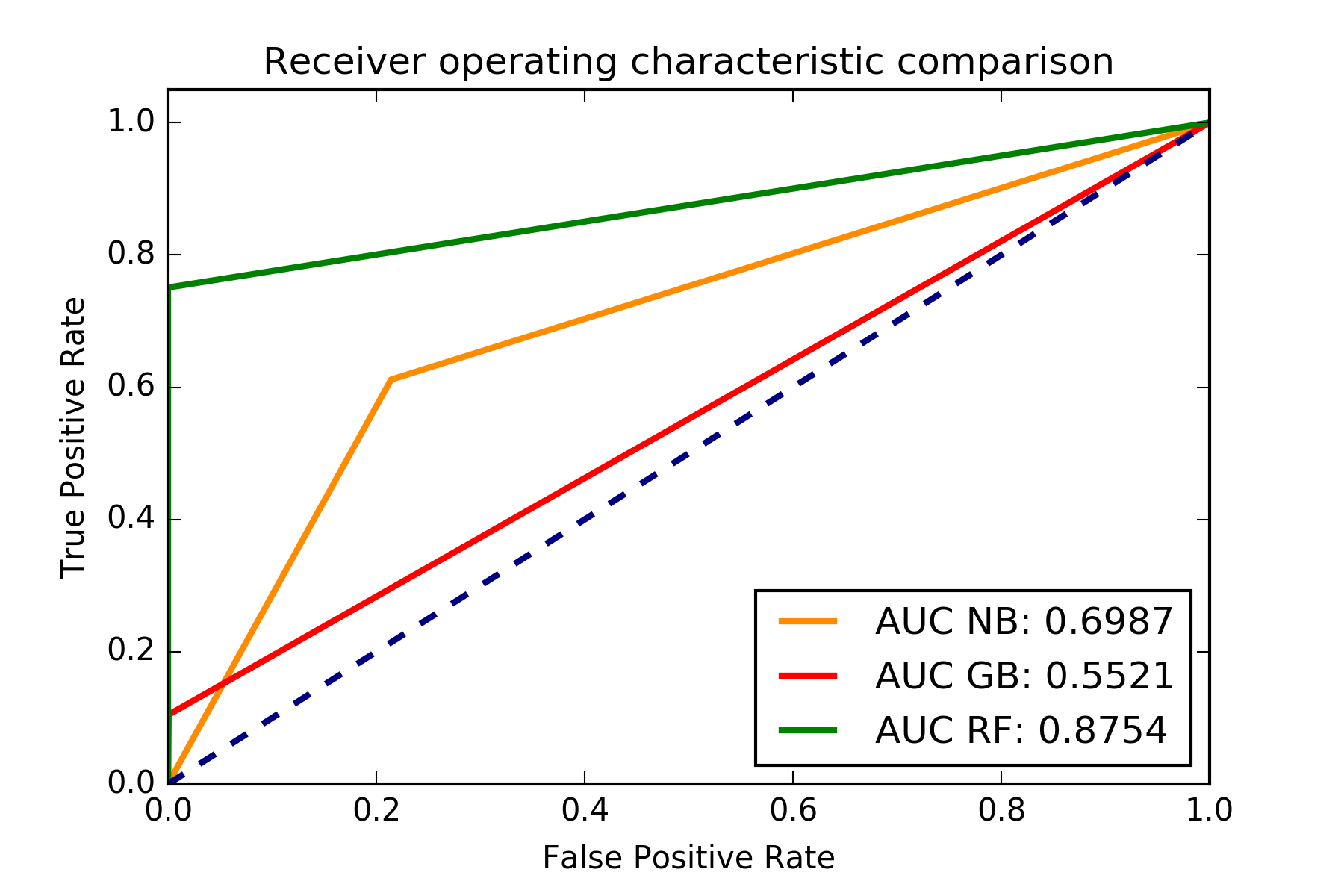 Figura con el ROC para los clasificadores. También se muestra el AUC. El mejor clasificador de los probados es el Random Forest.
Figura con el ROC para los clasificadores. También se muestra el AUC. El mejor clasificador de los probados es el Random Forest.
Selección final para el reto
Por último tratamos de inferir usando nuestros clasificadores si es razonable pensar que los registros del juego de datos de test con "TARGET" positivo se encuentran al final como en el juego de datos de training. Usamos nuestro mejor clasificador que es el Random Forest y se comprueba que hay una concentración significativa de resultados positivos al final y negativos al principio.
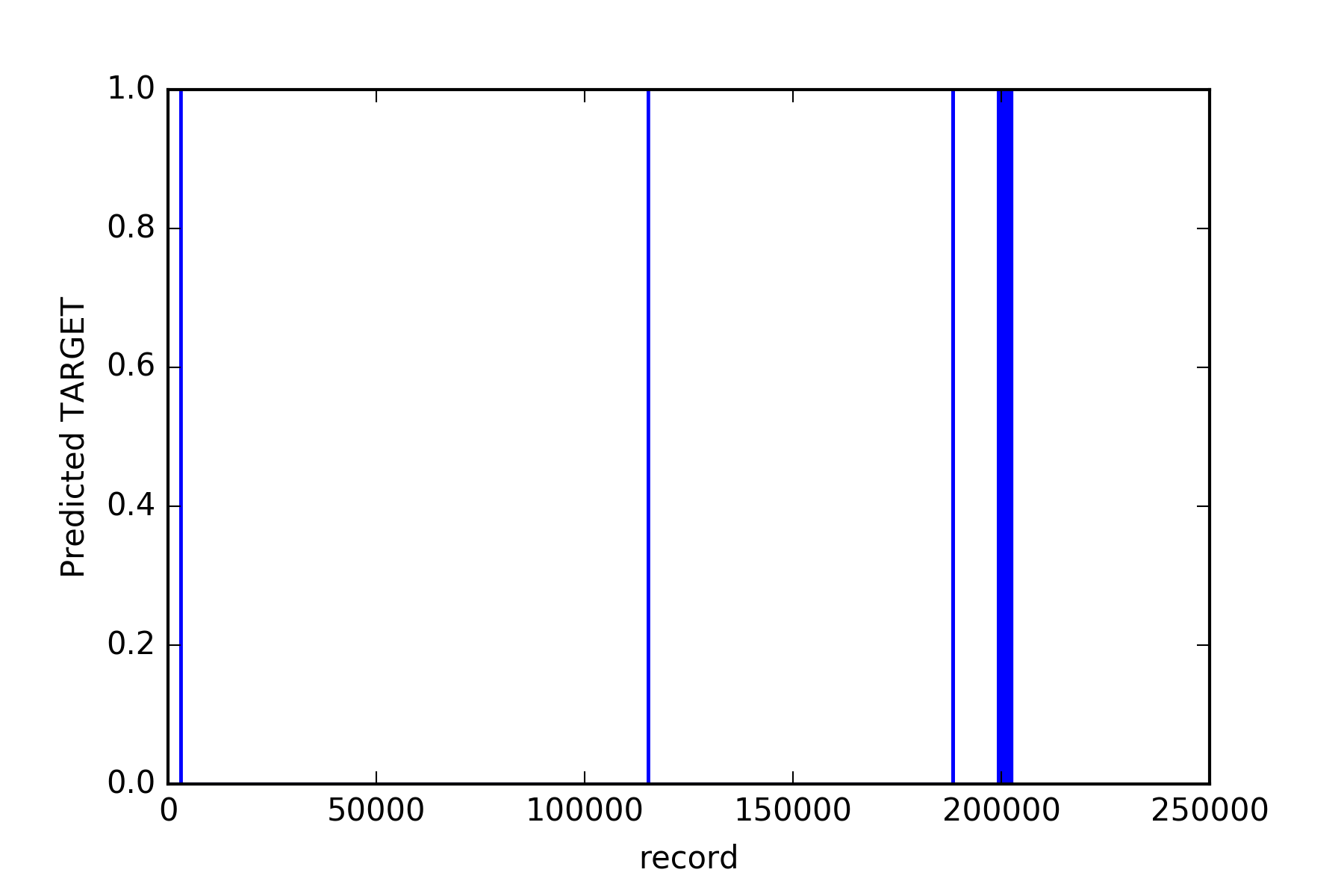 Concentración de datos con TARGET positivo al final del array.
Concentración de datos con TARGET positivo al final del array.
Para generar el resultado final hay dos opciones, una manual y otra que usa un clasificador de machine learning. La manual es asignar un TARGET negativo a todos los registros con ID menor que 663710 y un TARGET positivo a todos los que tienen un ID mayor que 663714. El corte se pone en algún lugar de los 4 registros entre 663710 y 663714 y se obtendría un AUC mayor que 0.999. La opción de machine learning es usar un algoritmo con regularización que tenga en cuenta el ID como un feature. Normalmente el peso del ID sera el determinante para la clasificación y se asignará un corte correcto en el ID adecuado. Nosotros usamos un Gradient Boosting Classifier que introduce el ID como un feature que genera el resultado final.
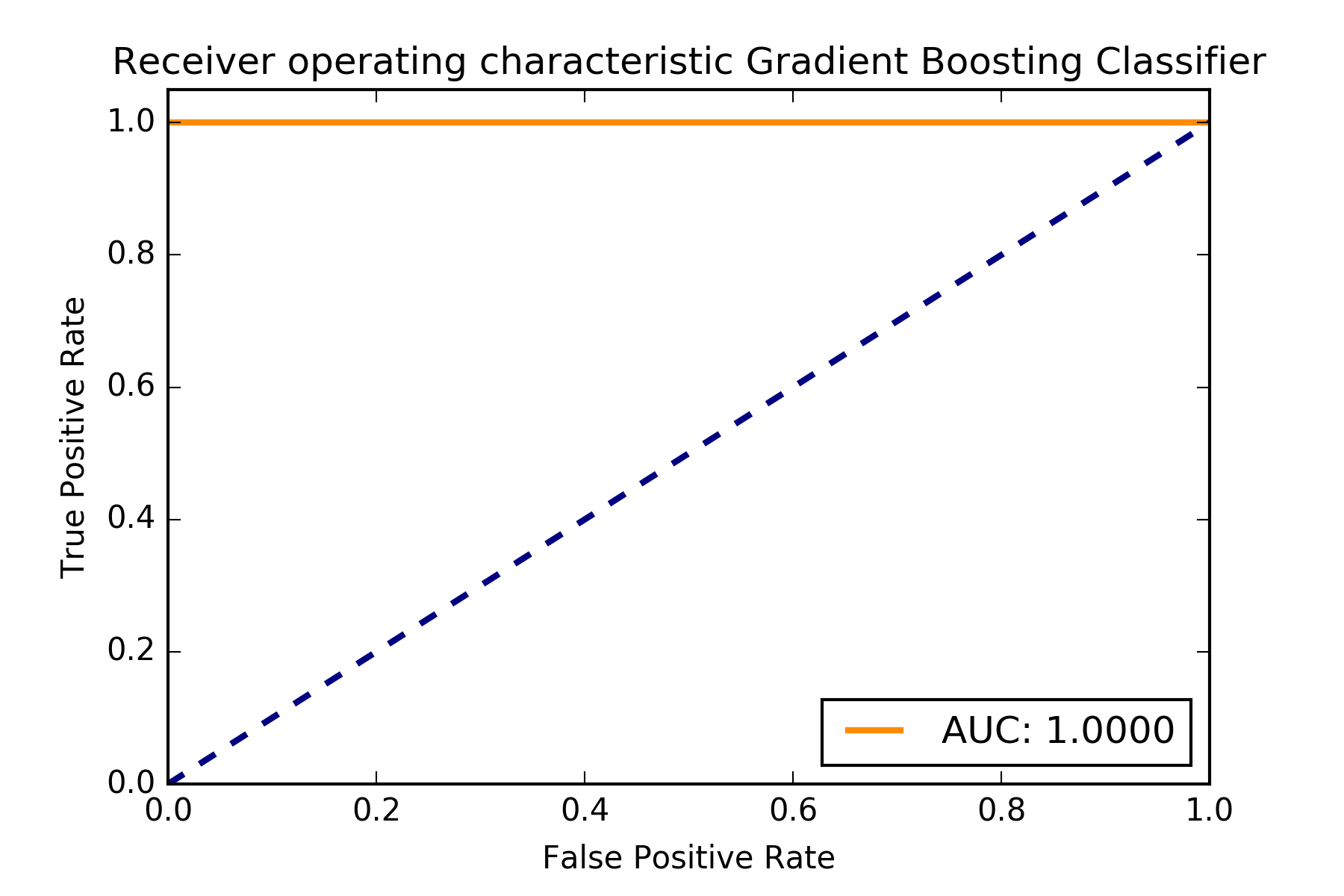 ROC final para los datos que usan el ID.
ROC final para los datos que usan el ID.
Los datos de clasificación final del reto se encuentran en formato json, npy o texto.
Material adicional
Finalmente añadimos material adicional generado en el estudio